Глава 1. Почему SQL Server поверх Linux?
Содержание
Microsoft SQL Server 2017 стал в целом доступным 2 октября 2017. Он был отмечен как 12й основной выпуск SQL Server в его истории. В настоящее время SQL Server является ведущей платформой данный в отрасли. Он запитывает вебсайты, индустрию и бизнес приложения по всему миру начиная с ноутбуков для малого бизнеса, вполоть до больших корпоративных серверов. Он используется в качестве платформы данных в частных и общедоступных облачных решениях. Механизм его базы данных является той мощью, которая стоит за Microsoft Azure SQL Database. SQL Server на протяжении долгих лет обладал величайшей репутацией простоты в применении, лёгкости в администрировании и как лидера в соотношении стоимость/ производительность. Однако SQL Server теперь становится и основной технологической силой благодаря революционным производительности и масштабируемости, гарантированной безопасности и новым интеллектуальным возможностям. Такие функции как индексация хранилища колонок, хранилище запросов, постоянное шифрование, базы данных графов, группы доступности Always On и службы машинного обучения демонстрируют, что SQL Server не просто великолепный механизм реляционной базы данных, но и реальная платформа для приложений. Наша гордая история совместной работы с Windows Server на протяжении долгих лет является невероятной историей. Тогда зачем же нам выстраивать SQL Server также и поверх Linux?
Я присоединился к Microsoft в 1993 после того как провёл семь лет в колледже участвуя в проектах разработки UNIX с применением C++ и баз данных подобных Ingres и ORACLE. Когда я присоединился к Microsoft, я полагал что мои дни с UNIX миновали. Конечно, на протяжении более чем 20 лет я стал неким экспертом в SQL Server исполняемым поверх Windows Server и я полагал что никогда не смогу увидеть исполнение SQL Server где либо ещё.
Затем в один из дней 2015, мой коллега Боб Дор со мной вместе получили некое письмо от Славы Окс, руководителя инженеров разработки для SQL Server, спрашивающего что бы мы подумали, если бы мы построили SQL Server, исполняемый под управлением Linux. Естественно, я прочёл сообщение несколько раз прежде чем я врубился в то что он предлагал. Я не особо задумывался об этом пока не посетил некое внутреннее мероприятие Microsoft в конце 2015. На этом мероприятии, к моему изумлению, Тобиас Тернстром, один из первоначальных управляющих данного проекта, продемонстрировал аудитории некое развёртывание SQL Server при помощи apt-get Ubuntu и подключение для исполнения запросов таким манером за минуты.
После того как я вернулся в своё кресло, у меня возник целый ряд вопросов. Как мы сделали это настолько быстро? Какая именно архитектура стояла за тем, чтобы взять такой выдающийся механизм и запустить его поверх Libux в столь короткие сроки. Но я также хотел знать и зачем. Наш продукт SQL Server пользовался громадным успехом в отрасли среди клиентов, работающих поверх Windows Server.
И именно это запустило отсчёт для данной книги. Я поясню наши мотивы перевода SQL Server на платформу Linux, основные принципы того, как мы это сделали, и его основные возможности. Я пользуюсь репутацией в имеющемся сообществе SQL Server по той причине, что представляю внутреннее устройство компонентов SQL Server, поэтому я не смогу помочь себе в этой главе и на протяжении всей книги. Время от времени вы будете заглядывать "за кулисы" относительно того как эта технология работает на платформе Linux.
В мае 2016 мы выпустили Microsoft SQL Server 2016, который стал 11 редакцией SQL Server, начиная с того как мы предложили 4.2 для Windows NT в 1993. Этот выпуск был упакован с основной функциональностью и был позитивно принят сообществом SQL Server. Одновременно с большой работой по запуску этой редакции команда разработчиков уже работала над SQL Server 2017, для которого ключевым заголовком в перечне функциональности могла бы быть наконец реализованная поддержка в SQL Server 2017 для Linux и контейнеров. Отрасль и весь мир уже знали что мы намерены сделать это в реальности, так как ранее в этом году Скотт Гатри, исполнительный вице- президент корпорации Группы облачных и корпоративных решений в Microsoft, объявил об этом на мероприятии для клиентов и в нашем официальном блоге. В этом блоге Скотт называет истинную причину внедрения SQL Server поверх Linux: "... перевод SQL Server в Linux является ещё одним способом сделать наши продукты и новы инновации более доступными для более широкого круга пользователей и встретить их на их собственном поле." Наше решение перенести SQL Server в Linux не было связано с отказом от Windows Server. Речь шла о создании великолепной платформы данных как для Windows, так и для Linux. Речь шла о предоставлении клиентам права выбора платформ. И мы не просто пришли к такому заключению без данных и свидетельств пользователей.
Во- первых, мы знали что в нашей отрасли наметилась тенденция относительно того, что Linux становится очень популярным. Сегодняшние исследования показывают, что около 30% корпоративных серверов в настоящее время используют какой- то дистрибутив Linux. Исследования независимых фирм, таких как Gartner, показывают, что серверы Linux - самый быстрорастущий сегмент ОС.
Во- вторых, в Microsoft мы сами обнаружили доказательства этого. Для виртуальных машин Microsoft Azure самой быстрорастущей гостевой операционной системой стала Linux. У нас имелись клиенты, которые размещали "смешанные" среды (Linus и Windows Server) и приходили к нам с вопросом, рассматриваем ли мы когда- нибудь в будущем доступность SQL Server поверх Linux. Дело не в том, что они отказывались от Windows Server, а в том что они желали выполнить стандартизацию SQL Server в своих компаниях, но им требовались варианты для Linux и Windows Server.
Наконец, партнёры Linux начали спрашивать нас не рассматриваем ли мы перемещения в Linux. Такие компании как Red Hat и SUSE наблюдали огромный рост своего корпоративного бизнеса и ощущали что предложение выбора платформ данных поможет адаптации клиентов.
Все эти факторы были в головах наших руководителей Инженерных разработок SQL Server в конце 2014 и в начале 2015 годов: Шон Бис, охан Кумар и Линдси Аллен. Они сыграли важную роль в том чтобы убедить наше исполнительное руководство в Microsoft позволить нам создавать SQL Server поверх Linux. И они наняли никого иного, как Славу Окса для этого построения и назначили Тобиаса Тернстрома руководить управлением программы проекта. Они создали удивительную команду из сотрудников для начала проекта, получившего название Хельсинки.
Теперь у нас имелись мотивация, одобрение и ресурсы для движения вперёд. И сейчас вопрос состоял только в том, как мы это создадим? И как быстро мы доставим это на имеющийся рынок?
Проект Хельсинки, SQL Server поверх Linux, является одним из самых удивительных достижений программного обеспечения, с которым я столкнулся за свои 25 лет в Microsoft. В этом разделе я продемонстрирую вам впечатляющую историю того как мы создали SQL Server для Linux и смогли вывести его на рынок с сохранением качества и производительности. В этом разделе я расскажу о важном программном компоненте, который именуется уровнем абстракции платформы SQL (SQPAL, SQL Platform Abstraction Layer) на основе проекта Microsoft Research с названием Drawbridge. Кроме того я обсужу архитектуру процесса и о том как взаимодействуют различные компоненты чтобы SQL Server заработал в Linux.
В марте 2011 команда Microsoft Research опубликовала статью с названием Rethinking the Library OS from the Top Down. Данная статья основывалась на неком прототипе проекта с названием Drawbridge и концепции, именуемой как библиотечная ОС (library OS). Если вы вспомните 2011 год, виртуализация была очень горячей темой и стала чрезвычайно популярной. Виртуальные машины были неким общим механизмом для осуществления консолидации проектов и абстрагировании приложений от лежащего в основе оборудования. Они предоставляли изолированность, совместимость и наличие возможности освободить вас от того чтобы полагаться на некий конкретный компьютер для размещения. Более того, они всё ещё популярны и всё ещё остаются сегодня в общедоступных средах, таких как Azure Virtual Machine и Amazon EC2. Единственная проблема состоит в том, что виртуальные машины являются тяжёлым ресурсом. То есть вам необходима операционная система целиком для запуска в вашем госте для поддержки вашего приложения, даже если вам не требуются все службы которые поставляются с такой гостевой операционной системой.
Команда Drawbridge (Разводной мост)искала способ создать нечто с меньшим весом, но сохранить преимущества виртуализации. Более того, они обнаружили в ходе их изысканий, что многие службы и вызовы API (интерфейсов прикладного программирования), требующихся приложениям Windows в действительности не обязаны выполняться внутри ядра Windows. Более предпочтительно наличие возможности запуска такого кода, который поддерживает многие API Windows в режиме пользователя, тем самым уменьшая переключения контекста основного ядра. Сокращение переключений контекста повышает производительность и приводит к более эффективным приложениям и использованию вычислительных ресурсов.
Основным результатом этого проекта было некое понятие с названием пикопроцесс (picoprocess), исполняемым в библиотечной ОС, действенно создавая PAL (Platform Abstraction Layer, Уровень абстракции платформы). Рисунок 1-1 отображает получаемую в результате архитектуру.
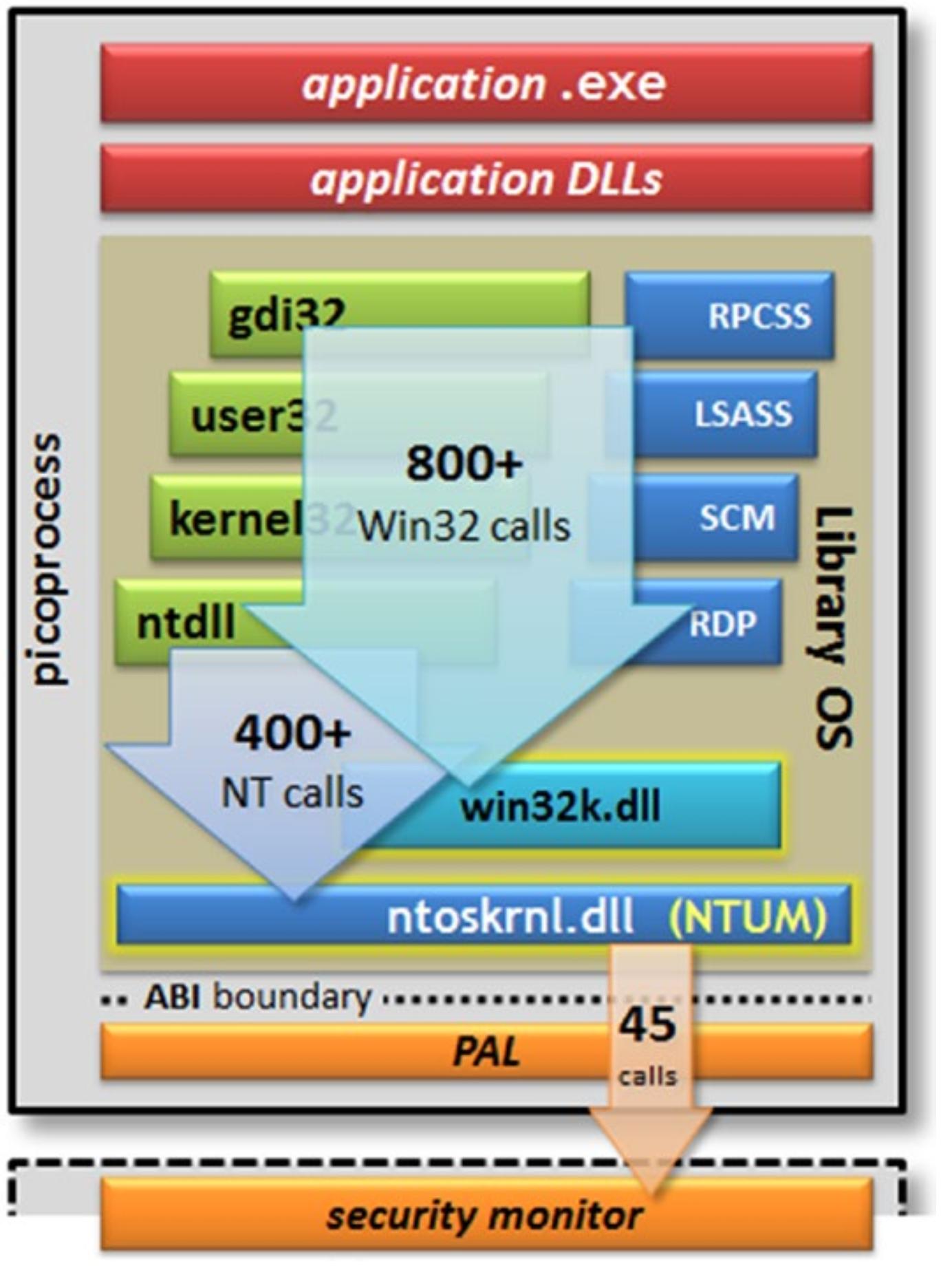
На Рисунке 1-1 сам пикопроцесс представляет некий двоичный файл, который сочетает ваше приложение и необходимые компоненты библиотечной ОС в обособленном процессе. Предесть данного подхода заключается в том, что ваше приложение и его DLL не изменяются. Не требуется никакая повторная компиляция или какие- то изменения. Именно эта магия позволила Славе и его команде включить эту концепцию и применить её в другой операционной системе такой как Linux и это двоичный интерфейс приложения (ABI, Application Binary Interface). Многие API Windows (на данной схеме они представлены вызовами Win32 и NT) реализуются в данном процессе самой библиотечной ОС, в то время как примерно 45 выставляются через имеющийся PAL и устанавливают соответствие своего ABI и в конечном счёте лежащей в основе ОС.
В это время Слава работал внутри Microsoft в проекте с названием Midori, который был другим проектом операционной системы и выпилил эту работу из команды Drawbridge. Он смог в сжатые сроки запустить приложение Windows на Midori, воспользовавшись работой команды Drawbridge . Поэтому, когда Славу попросили вернуться в группу разработчиков SQL Server и поработать над проектом по запуску SQL Server поверх Linux, его упражнения с Drawbridge сослужили огромную пользу.
Если вы задумаетесь о том выборе, который пришлось делать Славе и его команде для переноса SQL Server в Linux, наиболее логичным было бы портирование основного кода SQL Server для естественных компиляции и запуска в Linux. Но, как говорится, кодовая основа SQL Server целиком составляет миллионы строк кода. И хотя такой путь преобразования и компиляции SQL Server поверх Linux может и быть самым "чистым" подходом, не существует способа выхода на рынок в 2017 году, следуя таким путём. В действительности, ещё в 2014 году один из наших ведущих инженеров, Питер Бирн, оценил этот путь и пришёл к выводу: "Перенос и производство только основного кода механизма NT SQL в Linux потребует многих лет усилий и большой команды разработчиков/ тестировщиков и руководителей проекта". Следовательно, именно концепция Drawbridge оказалась некоторой идеей, заслуживающей рассмотрения.
Слава был участником той команды, которая создала некую составляющую SQL с названием SQLOS (кое- кто именовал её SOS), которая вошла в состав SQL Server 2005. Основная мысль состояла в том, чтобы абстрагировать само ядро механизма SQL Server настолько сильно, насколько это возможно, от лежащей в основе операционной системы для таких запросов как ввод/ вывод, обращения к памяти и потокам. И в SQL Server 2005 большая часть механизма была изменена для применения служб API SQLOS (через qldk.dll). SQLOS также предоставил встроенную поддержку для таких вещей как NUMA, управление ресурсами, мониторинг ресурсов и системы планирования, во многом аналогично ядру ОС. Его команда воспользовалась данным подходом, так как операционная система Windows не была целиком оптимизирована для служб подобных механизму базы данных. Я помню как спрашивал Славу много лет назад почему он ощущал необходимость создания SQLOS. Он ответил: "Ключевым наблюдением здесь является то, что планировщики СУБД и ОС обязаны сотрудничать сообща. Следовательно ОС обязана иметь встроенную поддержку СУБД, или же СУБД вынуждена иметь особый уровень планирования."
Когда вы читаете описание SQLOS и его возможность абстрагирования самого разработчика механизма SQL от лежащих в основе API интерфейсов операционной системы, вы можете подумать, а почему бы просто не взять SQLOS, не модифицировать её и не перекомпилировать полученный код поверх использование API ядра Linux? С таким подходом имелся ряд проблем:
-
Не весь механизм SQL применяет SQLOS при использовании API Windows. Например, имеющийся механизм напрямую выполняет вызов WriteFileGather() для сброса страниц данных на диск. Подтверждением этого является существование соответствующей формы типов ожиданий SQL Server. В SQL Server присутствует около 88 типов ожидания PREEMPTIVE_OS*, что демонстрирует насколько много компонентов не применяют SQLOS при использовании API Windows.
-
Нам всё ещё придётся выполнять повторную компиляцию своего кода SQL компиляторами Linux. Это может потребовать поддержки двух основ кода.
-
Существуют и прочие компоненты, которые могут исполняться вне имеющегося механизма, которые не пользуются SQLOS: например, наши компоненты, которые поддерживают XML в самом механизме и таких службах как агент SQL Server.
Когда я посмотрел на цели данного выпуска, мне стало понятно что их можно подытожить как Мы бы хотели запускать основную часть своего исполняемого кода, созданного для Windows, нетронутым в Linux. Быстро и надёжно, причём без внесения изменений в приложения..
Наличие SQLOS по- прежнему великое преимущество. Она обеспечивает основу для некого уровня абстракции который мы выстраиваем. Когда Слава и его команда попытались выполнить проектирование, они обнаружили что команда Drawbridge построила некий протоип своего проекта для работы в Linux. Теперь все части сложились в общую картину. Возьмём работу прототипа Drawbridge, внесём необходимые изменения для его воспроизводства и соединим это со своей работой и подходом SQLOS. Из этого родился SQLPAL.
![[Замечание]](/common/images/admon/note.png) | Замечание |
|---|---|
|
Я делаю это звучащим черезчур просто, хотя это и на самом деле один из самых удивительных и инновационных программных проектов, которые я когда либо видел за свою карьеру в Microsoft. |
Как рассказывает Слава, по истечению месяца с момента проектирования они получили простую работающую версию SQL Server, которая загружалась в Linux и выполняла запросы.
Слава оказался достаточно сообразительным чтобы запечатлеть фото этой самой первой загрузки, показанной на Рисунке 1-2.
Вскоре после этого Тобиас Тернстром и остальные члены команды получили некий план проекта и название для SQL Server поверх Linux. Они назвали его Проект Хельсинки (именуется в честь места рождения основателя Linux Линуса Торвальдса, где он разработал и предложил первоначальный проект Linux). Теперь, имея в виду некую архитектуру, этот проект теперь раскрутился на полную катушку по пути выпуска SQL Server поверх Linux в 2017 году.
Поскольку наша команда активно вносила все необходимые изменения в первоначальный проект Drawbridge и выстраивала все необходимые компоненты для развёртывания, настройки и инструментов, многие в отрасли и сообществе SQL Server любопытствуют, как мы создали всё это. Относительно требующегося простого развёртывания и основных возможностей запросов SQL Server в Linux были выполнены некие презентации, но никто не знал находящихся за сценой архитектуры, SQLPAL или применения Drawbridge в качестве некой концепции.
В конце 2016 наша команда решила опубликовать применяемую архитектуру. В результате получился исключительный блог одного из руководителей данного проекта, Скотта Коунерсманна. В этом блоге Скотт поведал историю Drawbridge, основные цели этого проекта и основные вызовы, предоставляемые от простого применения самого проекта Drawbridge. Основным ключом к успеху данного проекта был SQLPAL и Скотт суммировал то что им пришлось построить:
В результате изысканий мы решили остановиться на гибридной стратегии. Мы объединяем SOS и библиотечную ОС из Drawbridge для создания SQL PAL (SQL Platform Abstraction Layer, Уровня абстракции платформы SQL). Что касается тех областей Библиотечной ОС, которые не требуются SQL Server, нам их следовало удалить. Для слияния этих архитектур потребовались изменения на всех уровнях имеющегося стека.
Полученная новая архитектура состоит из набора непосредственных API SOS, которые не проходят через системные вызовы Win32 или NT. Для кода без непосредственных API SOS они будут осуществляться через некий размещаемый API Windows (такой как MSXML) или NTUM (API пользовательского режима NT - это более 1500 системных вызовов Win32 или NT). Все подсистемы, такие как управление хранилищем, сетью или ресурсами будут основаны на SOS и будут совместно использоваться напрямую SOS и API NTUM.
Подводя всему этому итог, окончательные архитектура и подход состояли в слиянии нашего имеющегося кода SQLOS с библиотечной ОС от Drawbridge для создания законченной концепции SQLPAL.
Скотт воспользовался схемой с Рисунка 1-3 для отображения имеющихся взаимодействий SQLPAL, SQLOS, библиотечной ОС и чего- то с названием Расширение хоста.

Я большой приверженец визуализации, поэтому когда я сам начал изучать обсуждаемую архитектуру, я решил изменить это представление на нечто более похожее на диаграмму на Рисунке 1-4 (Стоит отметить, что я основывался на более подробной схеме архитектуры, построенной самой командой Хельсинки.)

Раз я начал описывать имеющуюся архитектуру, позвольте мне предоставить ещё один важный комментарий. Это относится к архитектуре SQL Server 2017 в общем доступе. Как и со всеми прочими внутренними компонентами и архитектурами, мы оставляем за собой право изменять её и регулировать. Наша цель состоит в том чтобы пользователи не беспокоились об этих внутренних элементах, но с этим интересно разобраться и это обеспечивает доверие к успешности нашего продукта в Linux.
Я должен сказать вам, что предыдущая диаграмма и моё описание не совсем соответствуют той удивительной технологии, которая создана нашей командой. Возможно, понадобится целая книга, чтобы просто погрузиться в имеющуюся архитектуру. Я вижу как мы будем развивать эту архитектуру в будущем, чтобы упростить и улучшить её, поэтому даже целая глава относительно этого нецелесообразна. И наша цель состоит в том, чтобы пользователь SQL Server поверх Linux не заботился об этом. Но настолько много людей интересовались тем, как мы создавали SQL Server поверх Linux, что я подумал, что мне следует посвятить этому хотя бы один раздел данной главы.
Давайте вычленим все компоненты и то как они взаимодействуют при воссоздании данной архитектуры. Обратите внимание, что в данной схеме, в точности как и в Drawbridge, некий обособленный процесс Linux содержит само приложение (SQLSERVR.EXE), библиотечную ОС (LibOS) и наш PAL (в данном случае это SQLPAL). В качестве названия этого процесса в Linux выступает sqlservr. В сером блоке SQLSERVER представляет тот же самый двоичный файл SQLSERVR.EXE из Windows и его компоненты DLL, включая sqlmin.dll, sqllang.dll и прочие. LibOS находится из светло голубого блока это соответствующие DLL и службы Windows, которые поддерживают API Windows. Они включают в свой состав kernel32.dll, advapi32.dll и такие службы как RPCSS.EXE.
SQLPAL в светло голубом блоке имеет два компонента:
-
SQLOS: снаряжается из Windows в виде SQLDK.DLL
-
QLPAL.DLL: Именно она выступает тем ключевым компонентом, который будет реализовывать всю функциональность Windows, требующуюся со стороны LibOS или переправлять все вызовы, которым требуются службы ядра Linux в некий компонент с названием Host Extension (Расширение хоста). Неким примером той функциональности, которая реализуется в SQLPAL являются вызовы реестра Windows. неким примером того, что требует самого ядра Linux, выступает выделение памяти.
|
| Замечание |
|---|---|
|
Последующие версии SQLPAL могут полностью содержать в себе функциональность SQLOS, поэтому у нас есть возможность ещё больше упростить эти области кода. Например, SQLPAL.DLL сможет заключать в себе всю текущую функциональность, которая сегодня находится в SQLDK.DLL. |
Расширение хоста в чёрном блоке является набором кода, который естественным образом компилируется в Linux и понимает все необходимые вызовы API Linux для таких вещей как память (mmap), потоки (pthread) и ввод/ вывод (aio).
Мостом между этими двумя мирами является ABI (Application Binary Interface, Двоичный интерфейс приложения). Что это означает, так это то, что SQLPAL.DLL не может напрямую вызывать код Расширения хоста для памяти, потоков, ввода/ вывода и прочих служб, как вы это могли кодировать для любого API в Windows. Это происходит по той причине, что Windows и Linux имеют различные механизмы для вызова функций в коде (это именуется соглашением о вызовах). Поскольку SQLPAL.DLL скомпилирован поверх Windows, а код Расширения хоста скомпилирован поверх Linux, они обязаны общаться через некий механизм, который позволяет SQLPAL транслировать его соглашения о вызовах в Linux. Это осуществляется через хитрые последовательности инструкций сборки, поэтому это имеет название Двоичного интерфейса приложения (Application Binary Interface). Он обладает очень малым весом и не требует существенных затрат для выполнения такого перехода.
Если вы когда- либо изучали выполнение программ в операционных системах, таких как Windows или Linux, вам известно о так называемом двоичном формате программ в этих системах. Для Windows он имеет название формата Portable Execution (PE), а в Linux он именуется как формат Executable and Linkable Format (ELF). Любая компилируемая и связываемая программа в Windows применяет формат PE (например, SQLSERVR.EXE) и может исполняться только в Windows; и наоборот для двоичных файлов ELF в Linux. Итак, наш код Расширения хоста является частью процесса Linux SQLSERVR, компилируемый как двоичный ELF. Он имеет особую логику для того чтобы понимать как напрямую загружать SQLPAL.DLL, ибо это двоичный файл в формате PE, а также предоставляет ему необходимые ссылки для применения интерфейсов ABI в самом Расширении хоста (иными словами, наше Расширение хоста указывает SQLPAL как "общаться с ним в обратном оправлении на лету"). Наше Расширение хоста также знает как устанавливать соответствие со всеми двоичными файлами для SQLSERVR.EXE и LibOS из особым образом упакованных файлов на диске (мы более подробно обсудим это в Главе 2) в адресное пространство данного процесса. SQLPAL.DLL после этого знает как загружать SQLSERVR.EXE и впоследствии позволить происходить там загрузке обычных процесса Windows и DLL. Один ключевой момент здесь: весь это код скомпилирован для Intel- совместимых процессоров и следовательно, словами Роберта Дорра &qout;это всего- навсего код сборки&qout;. Это одна из причин, по которой наш код SQLSERVR.EXE работает в Linux без изменений.
Итак, чтобы просуммировать, SQLSERVR.EXE и его DLL зависимостей загружаются и исполняются в точности как они делают это в Windows. То же самое верно и для компонентов LibOS. SQLPAL.DLL скомпилирован для Windows, но имеет встроенную логику для реализации служб ядра Windows или же, в случае такой необходимости, вызывает прочие функции при помощи интерфейсов ABI для реализации определённых служб ядра. Однако SQLPAL.DLL не осведомлён о тех интерфейсах, которые реализованы в тех фрагментах кода, которые скомпилированы для Linux. Обо всём этом заботится имеющееся Расширение хоста.
На нашей схеме обсуждаемой архитектуры имеются ещё два других компонента, о которых я пока не говорил:
-
Обратите внимание, что SQLAGENT также перечислен на этой схеме. Это обусловлено тем, что когда вы устанавливаете SQL Server поверх Linux, вы загружаете SQLAGENT.EXE в самом процессе Linux SQLSERVR совместно с SQLAGENT.EXE. Я знаю что это странно, но это работает просто отлично. SQLPAL обеспечивает изоляцию процессов и эти процессы не осознают что они пребывают в одном и том де процессе Linux.
-
Отметьте в правом нижнем углу нечто с названием процесса Parent Watchdog. Позднее в этой книге вы узнаете о нём подробнее, но по своей сути это процесс с названием SQLSERVR, изначально скомпилированный для Linux и является той программой, которая запускается первой при старте SQL Server. Затем мы применяем вызов API fork() Linux для создания другого процесса SQLSERVR, который на самом деле является механизмом SQL Server и всеми его компонентами, которые вы наблюдаете на обсуждаемой схеме. Это обеспечивает удобную цель для мониторинга самого дочернего процесса SQLSERVR через сигналы для выполнения дампов и использования служб systemd для выполнения повторного запуска в случае необходимости. Вы можете прочесть дополнительные подробности об этом в следующем блоге. Эта взаимосвязь станет более очевидной в Главе 2, когда я буду обсуждать как устанавливается SQL Server поверх Linux.
Я осознаю, что всё это выглядит очень сложно, и это так и есть, но в то же время это также просто и элегантно. Именно эта архитектура позволила нам двигаться очень быстро, но с сохранением качества и производительности для вывода SQL Server на рынок Linux.
Я включил все эти подробности сюда не потому что вы обязаны их знать при применении SQL Server поверх Linux, а чтобы устранить путаницу относительно его работы и для повышения доверия к его проектированию и архитектуре.
И именно в этом состоит самый важный момент. Как вы узнаете уже в следующем разделе, ядро базы данных SQL Server - это всё тот же самый проверенный, масштабируемый механизм SQL Server, который мы применяли в тысячах серверов своих потребителей на протяжении всей истории данного продукта.
Я помню один разговор, который у меня был на эту тему со Славой Оксом, который сказал мне: "Боб, процессор запросов всё тот же процессор запросов". Эта цитата объясняет, почему мы смогли достичь сопоставимой производительности для SQL Server поверх Linux. Также это поясняет почему базы данных могут быть восстановлены на разных платформах и почему приложения могут подключаться к SQL Server поверх Linux практически без изменений, если они созданы для работы с SQL Server поверх Windows Server.
SQL Server 2017 имеет множество возможностей и свойств, нацеленных на производительность, безопасность и высокую доступность. Рассмотрим те возможности и свойства, которые доступны для SQL Server поверх Linux:
-
Некая центральная система SQLOS для планирования, управления памятью и руководства и управления ресурсами, которые предоставляют встроенные масштабируемость и распознают такие важные архитектуры сервера как NUMA
-
Компоненты механизма ядра для управления буфером, обработкой запросов, исполнением запросов, механизмом хранения и методами доступа
-
Основополагающие операции управления подобные BACKUP/ RESTORE, управлению индексами и командам DBCC (командной строки базы данных)
-
Наш знаменитейший язык T-SQL неизменно работающий за исключением какого- то числа свойств и возможностей, которые не поддерживаются в данном выпуске
-
Рабочие нагрузки в оперативной памяти, такие как индексация Хранилища столбцов и OLTP в оперативной памяти
-
Новые интеллектуальные свойства базы данных, такие как адаптивная обработка запроса (AQP,adaptive query processing) и Автоматическое регулирование (Automatic Tuning) (вы ещё услышите об этих свойствах дополнительно в Главе 4) на основе телеметрии Хранилища запросов (Query Store)
-
Группы доступности Always On (я применяю термин Availability Groups или AG для ссылки на свойства этих функций в данной книге) поддерживаются в полной функциональности. Как вы обнаружите в Главе 8, Группы доступности (AG) сопровождаются с основными возможностями восстановления после сбоев (кроме некоторых исключений) при помощи технологии кластеризации с названием Pacemaker. Кроме того, некоторые новые свойства из SQL Server 2017, предоставляемые для поддержки групп доступности без кластера там, где не требуется программное обеспечение для сопровождения кластеров
-
Экземпляр отказоустойчивого кластера Always On (AO FC) в Linux поддерживается с помощью Pacemaker
-
Свойства безопасности, такие как постоянное шифрование, динамическое маскирование данных, безопасность уровня строк, аудит и Прозрачное шифрование данных (TDE, Transparent Data Encryption)
-
Аутентификация SQL Serber и Active Directory при регистрации
-
Зашифрованные соединения поддерживаются с помощью TLS (Transport Layer Security)
-
Богатая функциональность программирования, такая как SQLCLR (только безопасные - SAFE - сборки), возможности T-SQL JSON и базы данных графов
-
Служба планирования Агента SQL Server поддерживает подсистему команд T-SQL
-
Поддерживаются SSIS (SQL Server Integration Services) для фундаментальных операций выделения, преобразования и загрузки (ETL)
-
В SQL Server поверх Linux инструменты работают "как есть", включая SQL Server Management Studio (исполняется в Windows), SQL Server Data Tools (исполняется в Windows) и прочие расширения mssql в соде Visual Studio (межплатформный инструментарий)
-
В Linux мы поддерживаем естественные инструменты командной строки , в том числе sqlcmd и bcp
-
Мы имеем встроенным новые кросс-платформные инструменты с открытым исходным кодом которые запускаются в Windows, Linux и MacOS работают с SQL Server поверх Linux или Windows: SQL Server Operations Studio и mssql-cli
-
Диагностика SQL Server, такая как расширенные события, представления динамического управления, предсталения каталога и возможности диагностики плана запроса
Может быть я упустил вашу любимую функциональность, но и этот перечень делает SQL Server поверх Linux крайне интересной историей. Полный список возможностей SQL Server поверх Linux можно найти в нашей документации.
Для тех из вас, читающих эту книгу, кто не знаком с редакциями SQL Server, важно знать что некоторые возможности имеются только в определённых редакциях. Для получения полного списка того какие функции в каких редакциях представлены обратитесь к нашей странице документации.
SQL Server 2017 поверх Linux предлагает следующие редакции:
-
Enterprise (Корпоративную): Это наиболее полно укомплектованная редакция. Она разработана для применения, как и у казанов её названии, в приложениях Корпоративных баз данных. С точки зрения лицензирования, имеются две разновидности Корпоративной редакции: Enterprise и Enterprise Core. Enterprise Core имеет все возможности, в то время как Enterprise обладает рядом ограничений по использованию конкретного числа вычислительных ядер. Enterprise доступна только для определённых пользователей, которые имеют договорные отношения с Microsoft.
-
Standard (Стандартную): Эта редакция разработана для предоставления основной функциональности SQL Server для приложений, имеющих целью подразделения меньшего размера или рабочие нагрузки со средним уровнем. Одно основное изменение сделанным в SQL Server 2016 SP1 было открытие некоторых функций в Стандартной редакции, которые ранее были доступны только для Корпоративной редакции. Смысл состоял в том, чтобы разработчики могли создавать приложения и не беспокоиться о том на какую именно редакцию нацелено их приложение. Имеются ограничения на размеры этих свойств для работы в данной Стандартной редакции, но они тем не менее теперь доступны. Дополнительно вы можете ознакомиться с этими изменениями в данном посте блога.
-
Developer (Разработчика): Это свободно распространяемая редакция, которая содержит все доступные в Корпоративной редакции функциональности. Тем не менее, согласно лицензии для данной редакции, она ограничивается только целями разработки для промышленного примененияю Вы можете применять эту редакцию для построения и проверки вашего приложения.
-
Web (Веб): Эта редакция подобна Стандартной, с более низкими пределами и специализированной стоимостью имеющей целью веб хостинг.
-
Express (Экспресс): Это самая базовая редакция, но она распространяется свободно и может применяться в промышленном использовании. Однако, она обладает достаточными ограничениями, которые не позволяют её применять ни для какого вида масштабируемых приложений. Тем не менее, если вы только что приступаете к SQL Server в качестве разработчика, вам может оказаться полезной SQL Server Express. Существует некий простой путь обновления её до Стандартной и Корпоративной редакций. В Linux SQL Server Express может обслуживать очень полезную цель в качестве сервера реплики только для настроек. Это более подробно будет обсуждаться в Главе 8.
Я так же должен упомянуть, что SQL Server предлагает и некую редакцию Evaluation (Оценочную). Она содержит все имеющиеся в Корпоративной редакции свойства, но не лицензируется для промышленного применения и имеет лицензию на основе срока действия. Но это также великолепный способ проверить возможности SQL Server в неком сервере Корпоративного уровня. В Главе 2 я опишу как вы можете выбирать какую именно редакцию вы желаете применять в SQL Server.
Для всей этой замечательной линейки свойств появляются некоторые области, которые недоступны (в плане обычной доступности) для SQL Server в Linux. Некоторые включаемые в продукт SQL Server функции имеют зависимости или требуют внешние программы, которые не так просты в доступности для работы в SQL Server поверх Linux.
|
| Замечание |
|---|---|
|
Мы активно изучаем многие из этих свойств с целью их включения в последующие версии или обновления SQL Server поверх Linux. |
Как и в любом ином выпуске поскольку существует фактор времени, мы принимаем жёсткие решения относительно того включать или нет функции или улучшения, которые мы бы хотели сделать. Тем самым, перечисленные ниже функции не были включены в SQL Server 2017 поверх Linux для общей доступности:
-
Репликации транзакций и слияний
-
Распределённые транзакции (привязанные к серверу запросы или распределённые транзакции приложения через MSDTC)
-
Stretch Database
-
Polybase
-
Службы машинного обучения (тем не менее, Естественные оценки - Native Scoring - поддерживаются)
-
Расширенные системные процедуры, такие как xp_cmdshell
Я перечислил только самые основные функции, которые не выполнены для общедоступного SQL Server 2017. Существует ещё какое- то число ограничений, и вы можете ознакомиться с исчерпывающем перечнем в Замечаниях к выпуску.
Я позволю себе добавить ещё один комментарий относительно редакций. Продукт SQL Server для Windows Server сегодня поставляется с прочими службами, такими как службы Анализа SQL Server (SSAS, SQL Server Analysis Services) и службами Отчётов SQL Server (SSRS, SQL Server Reporting Services). Они обычно именуются нашими службами Бизнес- аналитики (BI, Business Intelligence и также содержат службы Основных данных - MDS, Master Data Services и службы Качества данных - DQS, Data Quality Services). Эти службы не были реализованы для SQL Server поверх Linux. Обратите внимание, что данные службы имеют возможность подключения и выполнения запросов SQL Server поверх Linux.
Я завершу этот раздел ответом на вопрос, который обычно получаю: "Следует ли мне запускать SQL Server поверх Linux или Windows Server?" Ответ -Да (надеюсь, что мои читатели пока смеются). Дело в том, что мы построили SQL Server поверх Linux чтобы предоставить некий выбор, причём не потому что SQL Server работает быстрее под Windows Server или под Linux. Если функции, которые не поддерживаются сегодня в SQL Server поверх Linux не существенны для вас, принимайте решение на основе того, какая из платформ операционных систем лучше всего подходит именно для вас, для вашего приложения или для вашей компании. Некоторые клиенты с которыми я общаюсь заняты разработкой стандарта под Linux в своей организации, поэтому они сделают выбор в пользу согласованности и теперь SQL Server предоставляет им эту возможность. Для иных более комфортно с Windows Server и им нравится эта платформа, поэтому продолжайте оставаться с SQL Server на данной платформе. Для кого- то Linux является очень популярной операционной системой новых разработчиков, поэтому они с удовольствием будут строить приложения под SQL Server поверх Linux на стадиях разработки, а в промышленном применении могут применять SQL Server как под Linux, так и в Windows.
Мой приятель в службе поддержки Microsoft на протяжении долгих лет Роберт Дорр (вы можете найти нас обоих в нашем совместном блоге) присоединился к команде разработчиков Хельсинки в начале 2016 года. Когда я беседовал с ним об этой книге, он привёл мне воспоминание, которое подводит итог опыта всей команды и причины самого проекта:
"Я обнаружил себя ступившим на ракету- носитель. Для данной экосистемы предстоит ещё много чего нового что предстоит сделать. Лучше всего это описал Скотт Конерсманн, сказав что мы меняли реактивный двигатель посреди полёта, и в определённые дни это на самом деле было так. Мы привносим десятилетия испытанных и отлаженных технологий и опыта работы с Windows на платформу Linux и мы не хотим удалять его функциональность. Просто предоставьте самому потребителю принимать решение какой именно ‘движок’ он желает запускать."
Ещё одним важный мотив для нас относительно построения SQL Server под Linux состоял в поддержке новой технологии с названием контейнеры. Самая последняя глава этой книги рассмотрит технические подробности того как применять SQL Server с контейнерами. Здесь я поясню некие итоговые положения SQL Server в контейнерах и их взаимосвязь с Linux.
Новой появившейся силой в нашей отрасли для контейнеров, безусловно стал Docker. Вместо того чтобы создавать некое определение контейнеров своими словами, я абсолютно влюблён в то как сам Docker поясняет их:
"Образ контейнера - это обладающий малым весом, автономно исполняемый пакет программного обеспечения, который содержит в себе всё что требуется для его запуска: код, сборку времени исполнения, системные инструменты, системные библиотеки, настройки. Доступное как для Linux, так и для Windows упакованное в контейнеры программное обеспечение всегда будет работать одинаково, вне зависимости от своей среды. Контейнеры изолируют программное обеспечение от его окружения, например, отличия между средой разработки и промежуточными средами, а также помогают уменьшать конфликтность между командами, работающими с различным программным обеспечением в одной и той же инфраструктуре."
Прочтя это вы, вероятно, зададитесь вопросом, а почему бы нам просто не воспользоваться контейнерами вместо своей архитектуры SQLPAL?
Для этого имеется ряд основных причин:
-
Механизм Docker в Linux поддерживает только образы, содержащиеся в операционной системе Linux, так что запомните: контейнер взаимодействует с операционной системой самого хоста. Следовательно, если мы просто переедем в контейнеры, мы бы вернулись на круги своя относительно переноса всего своего кода в Linux.
-
Мы хотели предоставить собственные возможности непосредственно в самой операционной системе Linux для достижения максимальной производительности.
-
Даже несмотря на то, что мы желаем осуществлять полную поддержку SQL Server поверх контейнеров Docker и те новые сценарии, которые он предоставляет, мы бы не хотели всецело полагаться на это для поддержки Linux, в особенности если имеются некие ограничения для контейнеров, которые не будут естественным образом запускаться в Linux.
Меня вдохновляет будущее контейнеров Docker и то что SQL Server играет важную роль в превращении контейнеров в жизнеспособную технологию для новых сценариев, в том числе переносимость, согласованность и сценарии DevOps.
Я вспоминаю как не так давно спросил своего коллегу, Трэвиса Райта, одного из ключевых руководителей программ по выпуску SQL Server Linux, относительно поддержки SQL Server для контейнеров Windows. Его первый ответ озадачил меня. Он сказал: "Боб, почему это тебя волнует?" Его мысль состояла в том, что было бы неплохо попасть в тот мир, в котором основное внимание уделяется контейнеру базы данных, в том числе SQl Server, самой базе данных и всем фрагментам зависимостей вместо того чтобы беспокоиться о самой операционной системе в этом образе контейнера. Я никогда не думал об этом таким образом, и скорее всего мы пока не готовы к этому, но его идея очевидна. Это одна из перспектив контейнеров.
"Платформа" в таком контексте это сам хост в котором запущены контейнеры. Docker предоставляет эту независимость потому что я могу компоновать (compose, вы узнаете что это значит в нашей главе о контейнерах) некий образ Docker сервером SQL и запускать этот образ в качестве контейнера в Windows, Linux, MacOS или прочих облачных средах, таких как Azure Container Service (AKS), Amazon Elastic Container Service (ECS), Google Cloud Platform, Red Hat OpenShift и SUSE CaaS. А поскольку это некий контейнер, это тот же самый образ, запускаемый во всех этих средах. И именно это означает переносимость! Это предоставляет нам некий надёжный, согласованный пакет всем известной версии SQL Server совместно с вашей базой данных, сценариями или какими- то ещё зависимостями, которые вы помещаете в данный образ.
Вероятно вы уже слышали термин DevOps? Это понятие существует уже несколько лет и заключается в объединении ролей и задач для разработки программного обеспечения и операций. Он приобрёл популярность, поскольку представляет некий механизм, который позволяет сокращать жизненный цикл разработки и обеспечивать более частое развёртывание приложений.
Непрерывная интеграция/ непрерывное развёртывание (CI/CD continuous integration and continuous deployment) это методы для предоставления возможностей более действенной экосистемы DevOps. Применяя контейнеры, разработчики способны непрерывно выполнять интеграцию изменений своих приложений и развёртывать их в среды проверки и промышленного применения. Разработчики уже применяли эти технологии какое- то время, но платформы баз данных, такие как SQL Server обычно не составляли часть такого жизненного цикла. Некий обычный SQL Server предполагался размещённым в некотором сервере, а разработчикам приходилось попотеть чтобы поддерживать свои контейнеры с их приложениями в отсоединённом SQL Server и базах данных (и таких объектах как задания и сценарии агента SQL). Теперь, когда SQL Server влился в мир контейнеров, он теперь может быть частью контейнера, который содержится в имеющемся конвейере CI/ CD.
Перспектива контейнеров имеет гигантский потенциал для переносимости, согласованности и эффективности. Но как вы координируете выполнение многих контейнеров базы данных в конвейере CI/ CD или в крупномасштабной промышленной среде? Для решения этой проблемы была создана технология с названием Kubernetes. Kubernetes является системой с открытым исходным кодом для помощи с управлением, развёртыванием и оркестрацией многих контейнеров в единой экосистеме. Одним из его преимуществ является предоставление естественного решения высокой доступности для контейнеров, которое прекрасно сочетается с необходимостью для многих пользователей SQL Server предоставлять решения с высокой доступностью для промышленных баз данных. Kubernetes стал ведущим решением для масштабного управления и развёртывания контейнеров и был принят практически всеми поставщиками общедоступных облачных решений, которые поддерживают исполнение и развёртывание контейнеров.
Позднее в этой книге мы посвятим целую главу техническим подробностям развёртывания SQL Server с контейнерами Docker, включая примеры использования этого в конвейере CI/ CD и реализации Высокой доступности при помощи Kubernetes.